
Analysing the Quantity of Duplicated Code in Your Codebase
There are a lot of great tools out there to help you analyse source code for patterns, bugs, issues…etc. Normally one might take the time to install SonarQube somewhere and let it do the heavy lifting, but sometimes you don’t have the time or resources to do that. In this post I will talk about some simple tools and techniques you can use to find dupl icate code in your code base.
Tools
Analysis Goals
- Find percentage quantity of duplicate code (copy and pasted code)
- Present data to show that it is growing over time
- Visualize the growth of the code base growth and rate of growth of duplication
Why Do An Analyse
One of the key questions you might ask yourself before embarking on doing an audit of your code is, what is the point? Well in my view things like copy/paste programming are a code smell that indicate deeper issues. Why are programmers copying code rather than reusing for instance? Do they lack the skill or knowledge to do proper code sharing? Do you need to invest in training? Perhaps you are missing some sort of design layer and this is the only way programmers have found to cope? Perhaps your team is too rushed to do proper design and you might being running head long into big problems in the medium to long term?
Ultimately, for me that old expression “information is power” really captures it. A business wouldn’t go long periods without auditing their finances, or measuring the sales performance of their sales staff. Even the idea of evaluating employees is common places with quarterly/yearly reviews. Why don’t we scrutinize our code as keenly as business do their employees? The more data we have to hand the better decisions we can make, or at the very least we can see what decisions we are clearly not making.
Getting The Data
First you needed the data. If you are using source control (please tell you are using source control…) then this process should be quite straight forward. I’m working on a project at the moment, it’s a small WordPress site and happen to have the WordPress source on my machine. So why don’t we have a look at that code base?
The version I’m using is hosted on Github so I’ll be using Git to handle getting the right code. I’ve done this analysis with SVN as the VCS in the past and it’s quite straight forward to get code out of that too. Either way you’ll want to loop over a range of some sort. In my script I’ve hard code tag version of the code base to check out but if you were checking out revision numbers or were thinking about incrementing a date a great bash command to do this is seq. This is a great little tool for producing a number output based on a few parameters, using that command with a for in loop you have an easy looped range to work with.
In my script I use a sub-shell to perform the checkout/update. There isn’t really any reason to not have jumped into the working directory once and stay there for the duration of the work, but I wanted to keep my files outside of the source code area I was analysing because I didn’t want anything to happen to those files when jumping between versions/tags.
for revision in "2.0" "2.5" "3.0" "3.5" "4.0" "4.3.1"; do
...etc
echo "Working out revision: $revision"
(cd $WORKING_DIRECTORY && git checkout $tagVersion --quiet)
...etc
done
for revision in $(seq 1 100 1000); do
...etc
echo "Working out revision: $revision"
(cd $WORKING_DIRECTORY && svn up -r$revision --quiet)
...etc
done
Revision Date
With this WordPress analysis and other ones I’ve done I’ve needed the date to corresponding to the tag/revision I’m analysing. To do that my script used the following bash command. Relying on the assumption that we have just checked out the version of the code base we are about to look at. We gets the top commit from Git and grabs the grep the date and commit SHA.
(cd $WORKING_DIRECTORY && git log --max-count=1 | grep -E 'Date|commit')
In SVN you can do the same with svn info which presents information about your local working copy. If you grep the string “Last Changed Date:” then you should have just the line with your working copies last revision date on it. I’ve additional include the sed command that will remove the words “Last Changed Date:” to leave you with the pure date information.
search_pattern="Last Changed Date: "
(cd $WORKING_DIRECTORY && svn info | grep $search_pattern | sed -e 's/\($search_pattern\)*//g')
Duplicate Code
CPDs mission statement is explained on it’s website.
“Duplicate code can be hard to find, especially in a large project. But PMD’s Copy/Paste Detector (CPD) can find it for you!”.
And it is exceptionally good at doing just that. The great thing about the CPD tool is it tokenizes the language you are scanning and looks for duplication at that level. So any kind of difference in code formatting, comments, blank lines…etc do not throw it off. Renaming variables, method names or subtly changing an algorithm would thrown it out though so those lines will not show up in its output.
Once you have a snapshot in time of your code base you’ll be able to run the CPD tool across the code. Sometimes you might need to exclude certain directories for various reasons, such as not analysing 3rd party libraries or other parts of the code base that are not relevant. In the script I’ve included a “EXCLUDE_PATTERN” concept that allows you to exclude a directory in this way. It limited to excluding a single directory right now, but it’s easily extended.
There are a large array of languages that CPD supports. I usually like to try out the scanner a few times and inspected the kind of duplication it finds. In some JavaScript projects I’ve analysed I’ve felt 75 tokens was about right. But for WordPress/PHP it seems you’re best off ramping that up considerable. I’ve put the bar all the ways up to 200 tokens for this analysis.
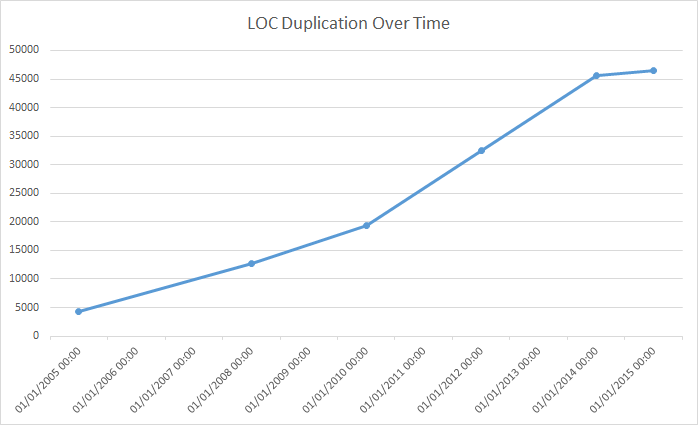
The kind of graphs you can get out of this analysis are interesting. Here we can see the raw quantity of duplicated code seems quite large and is growing fairly rapidly in the WordPress code base. When you look at the raw data however you find that a lot of duplication that does show up is really just a few lines here and there. The kind of thing that is difficult to avoid or even pointless to address. The key thing is to check out a sample of what is reported by CPD and see for yourself whether this figure is really as bad as it seems.
Total Number Of Lines Of Code
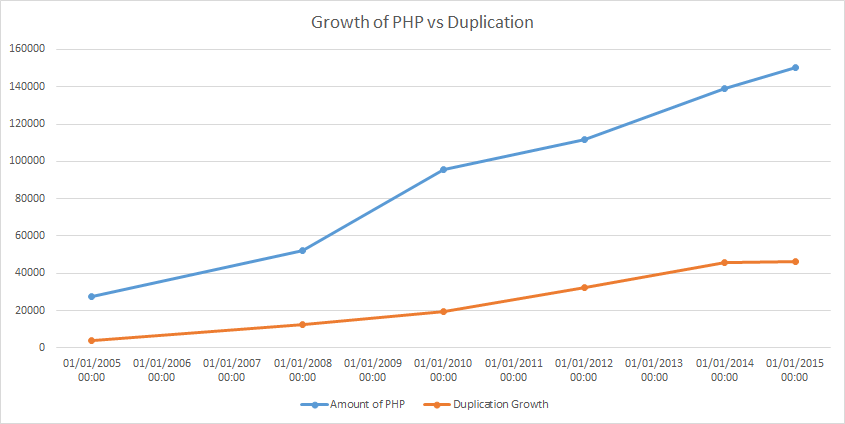
Graphing the duplication versus the total amount of code is a better way to gauge things. To get the figures for the total amount of code in the system I use a tool called cloc. The type of things you can find with these figures are if duplication and code base are growing at the same rate relative to one another (which is what you’d expect/normally find) or maybe the rate of duplication is clearly getting out of hand? Finally with this tool you can get the data that allows you to calculate the percentage amount of duplication versus the overall code base.
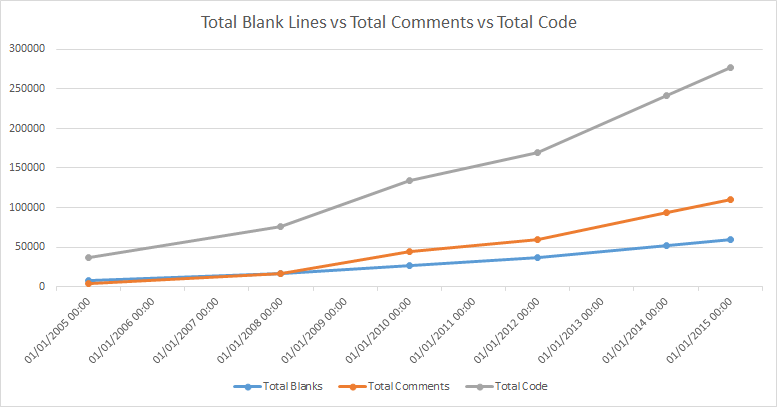
Cloc is a great tool for giving you insight into the amount of different languages in a code base. What I like about it is when it parses the code it can calculate the number of blank lines, comments and then total amount of code. Instead of a plain you have 100 lines of code you can find out you have 60 lines of code with a bunch of comments and blank lines. This is useful information.
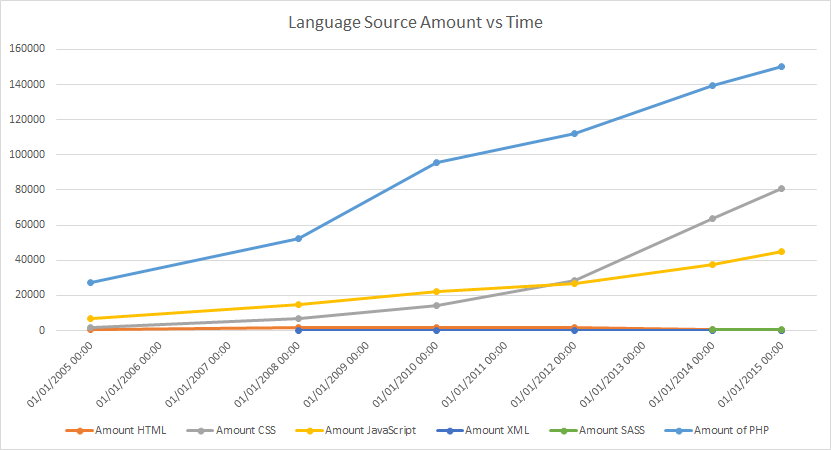
Here is a straight forward graph showing the growth of different languages over time. Obviously PHP was going to be winning out over everything else, and perhaps it’s not surprising to see that there is more CSS than there is JavaScript in the system. The really interesting thing for me is you can see that SASS is only really getting a foothold in the project and there doesn’t seem to be any big strides to move the CSS over to SASS at the moment.
The Future Of WordPress Language Usage
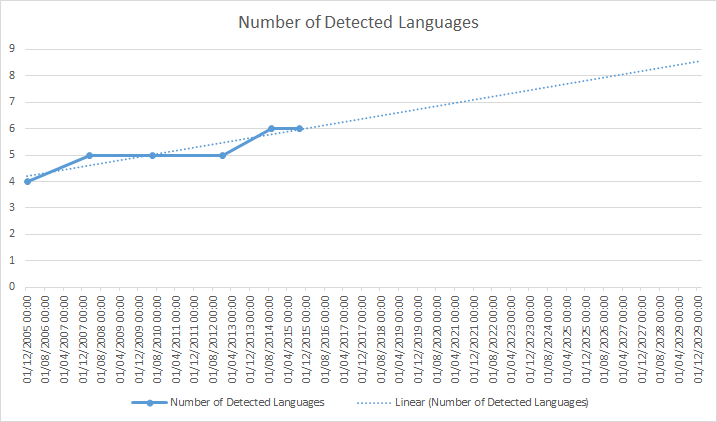
Some of the silly thing you can do with this data is to reason about the future of the project. For instance here you can see then number of languages that make up the source code and a graph projecting potential for new one over time. If these numbers are anything to go by WordPress will consist of 8 different languages by about 2026 :P.
Top Ten Biggest Files
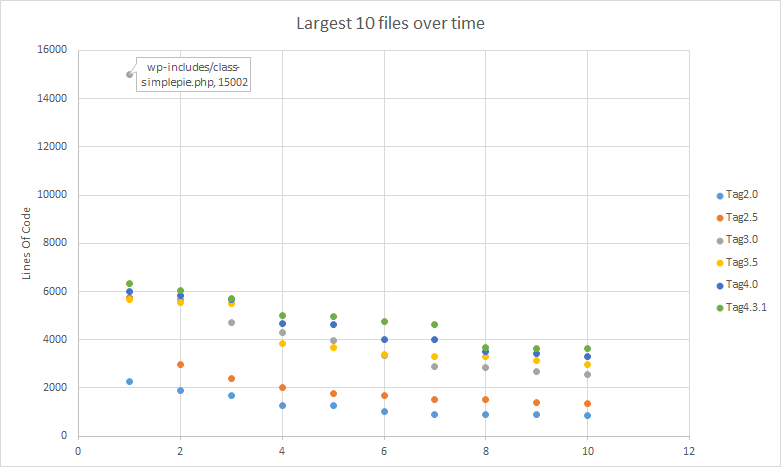
I’ve had this script kicking for a little while and recently I added something to it called top ten files. The basic idea is I can get an output of the top ten largest files (this is based on raw number of lines). The length of files can be a code smell like anything else and I figure it was an interested figure to graph either way. In the case of WordPress you can see that the size of the top ten files are increasing with each version, but are roughly the same length, except for one outlier in version 3.0.
Full Script
Here is the full script, warts and all. There is plenty of issues with it, but it was something I put together in a few minutes, so I’m not super concerned by it’s quality. There are few main components of the script;
- Configuration at the top.
- Turn on and off certain analyses.
- Turn on some debug printing.
- Turn on/off the deletion of temporary files (useful for debugging).
- The various methods for getting/cleaning the data.
- Main method:
- Cleaning up before starting.
- Looping over versions.
- Checking out code from VCS.
- Getting date information (if checking out code by date which is easy in SVN, not so much it other, it’s unnecessary).
- Running CPD and producing duplication data set.
- Produce an offset file which is the length of each duplication data set. Useful in Excel.
- Running CLOC.
- Getting the top ten biggest files.
- Creating the final output for duplication analysis.
- Removing temporary files.
#!/bin/bash
# Print some script debug information
CPCLOC_DEBUG_SCRIPT=true
WORKING_DIRECTORY="wp/"
LOCATION_TO_ANALYSIS="wp/"
EXCLUDE_PATTERN="themes"
EXCLUDE_PATTERN_PATH="wp-content/$EXCLUDE_PATTERN"
OUTPUT_LOCATION="cpd5.3.4"
# You can hang onto the temporary files to see if there is an error in the script
# and the data that it collects.
DELETE_TEMP_FILES=false
# Turn off parts of the script you don't want easier than commenting out stuff
CHECKOUT_DIFF_VERSION=true
CAPTURE_DATES=true
CAPTURE_DUPLICATION=true
CAPTURE_TOTAL_LOC=true
CAPTURE_TOP_FILES=true
# Support languages are the intersection of CPD & CLOC. You can always create parsers to add new supported languages to each.
# http://cloc.sourceforge.net/#Languages && https://pmd.github.io/pmd-5.3.4/usage/cpd-usage.html
SOURCE_LANG="php"
# Output format options: csv, csv_with_linecount_per_file, text, vs, xml
# Source: https://pmd.github.io/pmd-5.3.4/usage/cpd-usage.html
OUTPUT_FORMAT="csv_with_linecount_per_file"
TOKEN_SIZE="200"
CPD_LIB_DIR="/c/Development/pmd/lib"
# Adjust this in case CPD blows up while processing your code base.
# The values represents the number of Megabytes to allocate to the JVM
# heap.
JAVA_HEAP_SIZE="3072"
debugPrint() {
if $CPCLOC_DEBUG_SCRIPT ; then
echo "DEBUG::: $1"
fi
}
normalizeCpdOuput() {
# Remove the titles of the columns
grep --invert-match "occurrences"
}
cutCpdOutputFields() {
# 1=Number of duplicated token
# 2=Number of detected file with duplication
# 4=Number of lines of duplication
# For CPD 5.3.4 and csv_with_linecount_per_file
cut --delimiter="," -f 1,2,4
}
runCpd() {
tagVersion=$1
# Making Cpd similar to cloc with regards to exclusion paths
excludeDir="$WORKING_DIRECTORY/$EXCLUDE_PATTERN_PATH"
java -Xmx${JAVA_HEAP_SIZE}m -cp "$CPD_LIB_DIR/*" net.sourceforge.pmd.cpd.CPD --minimum-tokens $TOKEN_SIZE --files\
"$LOCATION_TO_ANALYSIS"\
--language "$SOURCE_LANG" --format "$OUTPUT_FORMAT"
}
printSourceControlDateForVersion() {
# SVN: (cd $WORKING_DIRECTORY && svn info | grep "Last Changed Date:" | sed -e 's/\(Last Changed Date: \)*//g')
(cd $WORKING_DIRECTORY && git log --max-count=1 | grep -E 'Date|commit')
}
# I've account for the output format in here. You really only have two options though,
# XML and CSV since those are the only other compatible options for CLOC/CPD intersection
printLocMetrics() {
if [[ $OUTPUT_FORMAT == *"csv"* ]]; then
CLOC_OUTPUT_FORMAT="--csv"
fi
if [[ $OUTPUT_FORMAT == *"xml"* ]]; then
CLOC_OUTPUT_FORMAT="--xml"
fi
if [[ $EXCLUDE_PATTERN != "" ]]; then
CLOC_EXCLUDE="--exclude-dir=\"$excludePattern\""
fi
cloc $LOCATION_TO_ANALYSIS --quiet $CLOC_EXCLUDE $CLOC_OUTPUT_FORMAT
}
printDuplicateFileMetric() {
tagVersion=$1
# Couldn't get the output of CPD to pipe properly for me for some reason, making temporary file
runCpd "$tagVersion" > "$OUTPUT_LOCATION/temp$tagVersion.temp-csv"
cat "$OUTPUT_LOCATION/temp$tagVersion.temp-csv" | cutCpdOutputFields | normalizeCpdOuput
}
main() {
echo "Script starting"
echo "."
echo ".."
echo "..."
echo "Removing files before starting"
rm --force ${OUTPUT_LOCATION}/*.csv
rm --force ${OUTPUT_LOCATION}/all.txt
rm --force ${OUTPUT_LOCATION}/tagLoc.txt
rm --force ${OUTPUT_LOCATION}/topFiles.txt
echo "---"
mkdir --parents "$OUTPUT_LOCATION"
debugPrint "Java Heap Size - $JAVA_HEAP_SIZE"
debugPrint "Cpd Lib Dir - $CPD_LIB_DIR"
debugPrint "Token Size - $TOKEN_SIZE"
debugPrint "Location To Analysis - $LOCATION_TO_ANALYSIS"
debugPrint "Source Lang - $SOURCE_LANG"
debugPrint "Output Format - $OUTPUT_FORMAT"
for tagVersion in "2.0" "2.5" "3.0" "3.5" "4.0" "4.3.1"; do
if $CHECKOUT_DIFF_VERSION ; then
echo "Working out tag: $tagVersion"
# I'm suppressing the Git checkout STDOUT here because I don't care.
(cd $WORKING_DIRECTORY && git checkout $tagVersion --quiet)
fi
if $CAPTURE_DATES ; then
echo "Getting release date for this version"
printSourceControlDateForVersion >> "$OUTPUT_LOCATION/tagDates.temp-csv"
echo "---"
fi
if $CAPTURE_DUPLICATION ; then
# I end up creating a lot of unnecessary temporary files. Must improve my bash-fu.
echo "Analysing duplicate code for this version"
printDuplicateFileMetric $tagVersion > "$OUTPUT_LOCATION/file.temp-csv"
numberOfRecords=$(cat "$OUTPUT_LOCATION/file.temp-csv" | wc --lines | tr --delete "[:space:]")
echo "Tag$tagVersion,offset,$numberOfRecords" >> "$OUTPUT_LOCATION/offsets.temp-csv"
echo "Tag$tagVersion" > "$OUTPUT_LOCATION/$tagVersion.csv"
cat "$OUTPUT_LOCATION/file.temp-csv" >> "$OUTPUT_LOCATION/$tagVersion.csv"
fi
if $CAPTURE_TOTAL_LOC ; then
echo "Analysing code base total size for this version"
echo "Tag$tagVersion" >> "$OUTPUT_LOCATION/tagLoc.txt"
printLocMetrics >> "$OUTPUT_LOCATION/tagLoc.txt"
fi
if $CAPTURE_TOP_FILES ; then
echo "Capturing the top 10 files for this version"
echo "Tag$tagVersion" >> "$OUTPUT_LOCATION/topFiles.txt"
find $LOCATION_TO_ANALYSIS -name "*.$SOURCE_LANG" -not -path "*$EXCLUDE_PATTERN*" -exec wc --lines '{}' \; | sort -rn | head --lines=10 >> "$OUTPUT_LOCATION/topFiles.txt"
fi
done
if $CAPTURE_DUPLICATION ; then
cat ${OUTPUT_LOCATION}/*.csv > ${OUTPUT_LOCATION}/all.temp-csv
cat ${OUTPUT_LOCATION}/tagDates.temp-csv ${OUTPUT_LOCATION}/offsets.temp-csv ${OUTPUT_LOCATION}/all.temp-csv > ${OUTPUT_LOCATION}/all.txt
fi
if $DELETE_TEMP_FILES ; then
echo "Cleaning up temporary files"
rm --force ${OUTPUT_LOCATION}/*.temp-csv
fi
}
main
Excel Formulas
Inside of Excel I used a few basic formulas after I got all of my data into it.
Duplicate Lines Of Code Per Duplicated Section
First, since I had my columns of data about duplicated code I wanted the number of lines of code that could theoretically be deleted or at least redesigned properly. When duplicate lines are being presented in CPDs output; it displays the chunk of code and all the places it shows up. This includes the location of the single representation that you potentially want to keep. No problem if you account for that in your formula.
n = Number of files
d = Duplicate lines of code
(n*d)-d
Once you have a column of these figures you can sum up all those totals and have an overall total amount of lines (per version/revision) that might need immediate attention.
Fancy Excel Foot Work
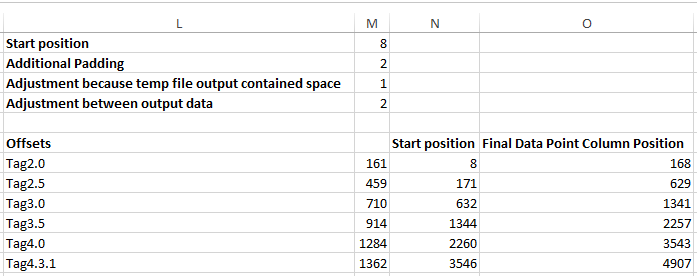
When you do this analysis a few times you start to loath scrolling. Some of the data sets I end up with are 15K+ lines long (when you concatenate them all together). That’s a lot of scrolling, so when I output my data I make sure to measure the size of the data so I have a series of offsets for each file. Then using Excels “INDIRECT” function I can do a SUM on a range of data without having to scroll up and down on it.
D = The column containing my calculated data.
N8 = Contains the value of the starting position for range.
O8 = Contains the value of the finishing position for range.
=SUM(INDIRECT("D"&N8&":D"&O8))
With this formula I am able to SUM big chunks of an Excel file without having to scroll. I just need to calculate the start and end position of each set of data which is easily done using the offset data I collecting during analysis of the source code.
Total Percentage Of Duplicated Code In The System
If you have the total amount of code in your system and the total duplication it’s natural to want the percentage duplication as well. With some basic math we get a value that represents 1% of the total overall code in the code base and then we divide that figure into the number of detected duplicate lines of code. Now you have the percent duplicated lines of code in your system.
d = total duplicate lines of code (per revision)
t = total amount of overall code (excluding comments and blank spaces)
d/(t/100)
Graphing Data; Dates Starting At Different Times But On The Same Graph
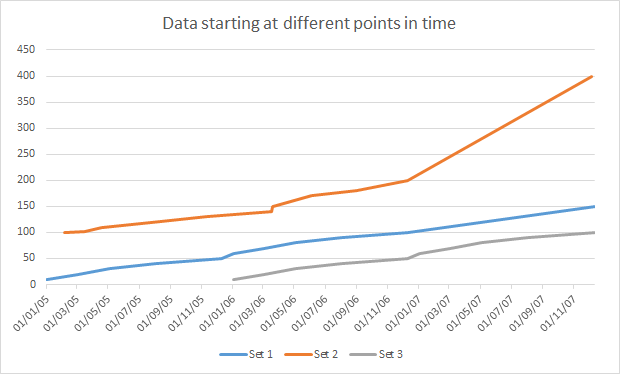
In past analyses I sometimes end up with a number of piece of data starting at different points in time. At first you’d think this should be easy to graph, just grab the series of data and Excel will figure it out. But that can result in weird incorrect graphs where everything start at the same time. The way to handle this situation is to look at/arrange your data properly. I didn’t figure this out on my own, I landed on a blog post by an author called Jon Peltier who gives a good step by step guide.
The basic thrust of the articles says that the graph component is very smart when it comes to dates, but you have to organise your data in a certain way for it to figure things out. So if you have two or more stacks of data starting at different points in time arrange the like so.
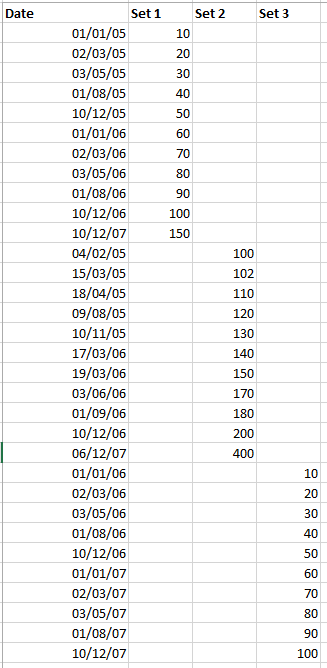
Your dates will all be in column (A) and your corresponding data in the other (three in my example) columns. When you go to graph the data you have something pretty decent. The only trouble then is gaps.

To get over this right click on the graph and you should get the option “Select Data” (Excel 2013 anyway) and on this new modal you’ll have a button with “Hidden and Empty Cells” which allows you set the behaviour for data with gaps that appear in the set. Choosing “Connect data points with lines” should help resolve the broken graphed data.
Tools That Could Of Helped
After doing this analyse I was curious as to other approaches I could of taken. I did a bit of Googling and found some interesting possible tools that could of helped me do this even quicker.
CSVKit
CSVKit is a great tool for working with CSV files at the command line. The work I did in excel for calculating the number of duplicate lines could of been calculated using this. I might of just ended up with a smaller set of figures and less work in the Excel document overall.
StatSvn & GitStat
I recently tried StatSvn against a code base I’ve been working on, but found that it was very slow and eventually exploded in the process. Because of the central nature of SVN, network traffic and load on the server can have an effect on your ability to get the log data StatSvn needs. The last time I used this tool I had tried to index and analyse everything in the repository (which was very, very large) which would explain why it would of fallen over. If you are using it on a very large code base, it’s probably best to get it to work on a subsection of your code base rather than the whole thing like I did.
Conclusion
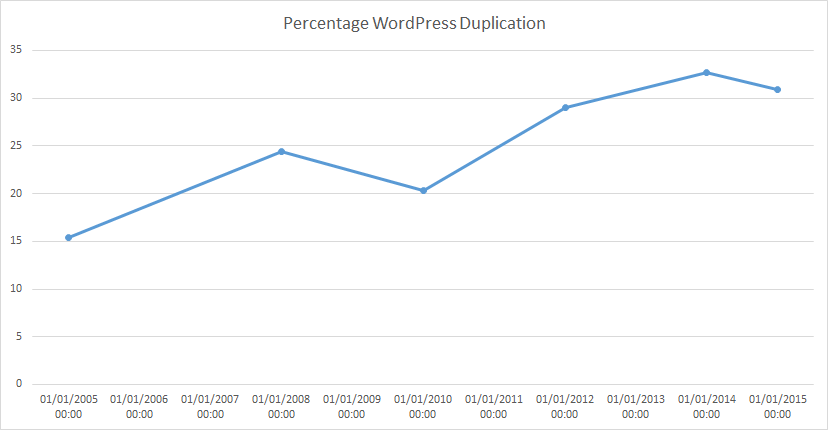
Sometimes you are in a position where it doesn’t really make sense to have to invest in a big tool/infrastructure or large amount of time to analysis your source code. A side project for instance. Much of the time gathering a little data can get you 90% of the value a bit system like SonarQube could. But sometimes you do need those system and when you do, you should absolutely set them up.
The advantage of sitting down and dealing with numbers in this kind of primitive way is it gives you a sense of your code base, it makes you curious and want to find more involved and interesting figures.
If you’d like to see some of that data I used to create my graph above, feel free to download it and inspect it for yourself.
Reference
Title Image
- The title image was a cropped version of “Analytics Red People Tracking” by uglowp
Data
- WordPress analysis data used to create graphs.
Articles
- “Plot Two Time Series With Different Dates” by Jon Peltier